#+STARTUP: overview indent inlineimages logdrawer
#+TITLE: C028AL-W2
#+AUTHOR: Arnaud Legrand
#+TAGS: noexport(n)
* Test et informations :noexport:
* Internal refs/notes :noexport:
** Images
- Notebook konrad:
- file:../slides-module2/jupyter-grippal-full.png
- file:../slides-module2/jupyter-grippal-top.png
- file:../slides-module2/jupyter-grippal-bottom.png
#+begin_src shell :results output :exports both
cd /home/alegrand/Work/Documents/Enseignements/RR_MOOC/slides-module2
file jupyter-grippal-full.png
rm /tmp/cropped_*
convert -crop 1345x3000 jupyter-grippal-full.png /tmp/cropped_%d.png
convert /tmp/cropped_*.png +append jupyter-grippal-paged.png
#+end_src
#+RESULTS:
: jupyter-grippal-full.png: PNG image data, 1345 x 8772, 8-bit/color RGBA, non-interlaced
#+begin_src shell :results output :exports both
cd /home/alegrand/Work/Documents/Enseignements/RR_MOOC/slides-module2
convert -scale x1507 jupyter-grippal-paged.png ../assets/img/nb3.png
#+end_src
#+RESULTS:
- Notebook Elisabeth: https://bitbucket.org/elizabethpwalton/smpe_project
#+begin_src shell :results output :exports both
cd /home/alegrand/Work/Documents/Enseignements/RR_MOOC/slides-module2
file elizabethpwalton_SMPE.png
rm /tmp/cropped_*
convert -crop 820x2650 elizabethpwalton_SMPE.png /tmp/cropped_%d.png
convert /tmp/cropped_*.png +append elizabethpwalton_SMPE-aged.png
#+end_src
#+RESULTS:
: elizabethpwalton_SMPE.png: PNG image data, 820 x 15217, 8-bit/color RGBA, non-interlaced
#+begin_src shell :results output :exports both
cd /home/alegrand/Work/Documents/Enseignements/RR_MOOC/slides-module2
convert -scale x1507 elizabethpwalton_SMPE-aged.png ../assets/img/nb4.png
#+end_src
#+RESULTS:
- Notebook Ismail:
#+begin_src shell :results output :exports both
cd /home/alegrand/Work/Documents/Enseignements/RR_MOOC/slides-module2
rm /tmp/cropped_*
convert -crop 590x1400 oscar.png /tmp/cropped_%d.png
for i in /tmp/cropped_[1-9].png ; do mv $i `echo $i | sed 's/cropped_/cropped_0/'` ; done
convert /tmp/cropped_*.png +append And_the_Oscar_goes_to-paged.png
#+end_src
#+RESULTS:
#+begin_src shell :results output :exports both
cd /home/alegrand/Work/Documents/Enseignements/RR_MOOC/slides-module2
convert -scale x1507 And_the_Oscar_goes_to-paged.png ../assets/img/nb5.png
#+end_src
#+RESULTS:
- Navette russe: https://io9.gizmodo.com/more-sad-remains-of-the-soviet-buran-space-shuttle-prog-1733190814
- Msieur il marche mon programme: https://www.luc-damas.fr/humeurs/images/il-marche-mon-programme.jpg
- PhD Comics:
- http://phdcomics.com/comics/archive.php?comicid=1947:
http://phdcomics.com/comics/archive/phd050817s.gif
- http://phdcomics.com/comics/archive.php?comicid=1948:
http://phdcomics.com/comics/archive/phd051017s.gif
** Graphe syndrome grippal:
#+begin_src shell :results output raw :exports both
debtree python3-matplotlib > python3-matplotlib.dot
sed -i -e 's/rankdir=LR/rankdir=RL/g' \
-e 's/node \[shape=box\]/node [shape=box, color=black, fillcolor=gray, fontcolor=black, style=filled]/g' \
python3-matplotlib.dot
dot -Tpng python3-matplotlib.dot > python3-matplotlib.png
echo file:python3-matplotlib.png
#+end_src
#+RESULTS:
file:python3-matplotlib.png
#+begin_src shell :results output :exports both
mv python3-matplotlib.png ../assets/img/
#+end_src
#+RESULTS:
* C028AL-W0-S0 (\approx 2:00); Introduction :noexport:
:LOGBOOK:
- State "TODO" from [2018-01-29 lun. 14:29]
:END:
** La recherche reproductible
*La recherche reproductible* s'intéresse à la mise en oeuvre et à la
promotion de meilleurs pratiques de recherche, et ce aussi bien sur le
plan technique qu'épistémologique.
*Petite bio, parcours, activité actuelle*: Pourquoi nous nous y
intéressons ?
Que vous preniez des notes, que vous génériez des figures, de gros
calculs ou des analyse de données, la recherche reproductible peut vous
intéresser.
Allons-y! :)
** Structure du cours
- *Cahier de notes, cahier de labo*
- *Le document computationnel*
- *Une analyse réplicable* Pour le premier module, pas de prérequis particulier. À partir du
2ème, on suppose une familarité avec les langages de programmation
python ou R.
A. Intégration Gitlab Jupyter
B. R/Rstudio,
C. Org-Mode
À ce stade, vous devriez commencez à maîtriser des outils modernes
permettant de singulièrement améliorer votre quotidien. Mais la
route est longue. Nous vous présenterons donc dans le dernier
module, les
- Autres défis de la recherche reproductible
Ce module ci est plus technique mais vous permettra de prendre du
recul et de bien identifier les difficultés spécifiques à votre
domaine et auxquelles vous serez confrontés.
* C028AL-W2-S0 (\approx 2:00); Vers une étude reproductible : la réalité du terrain
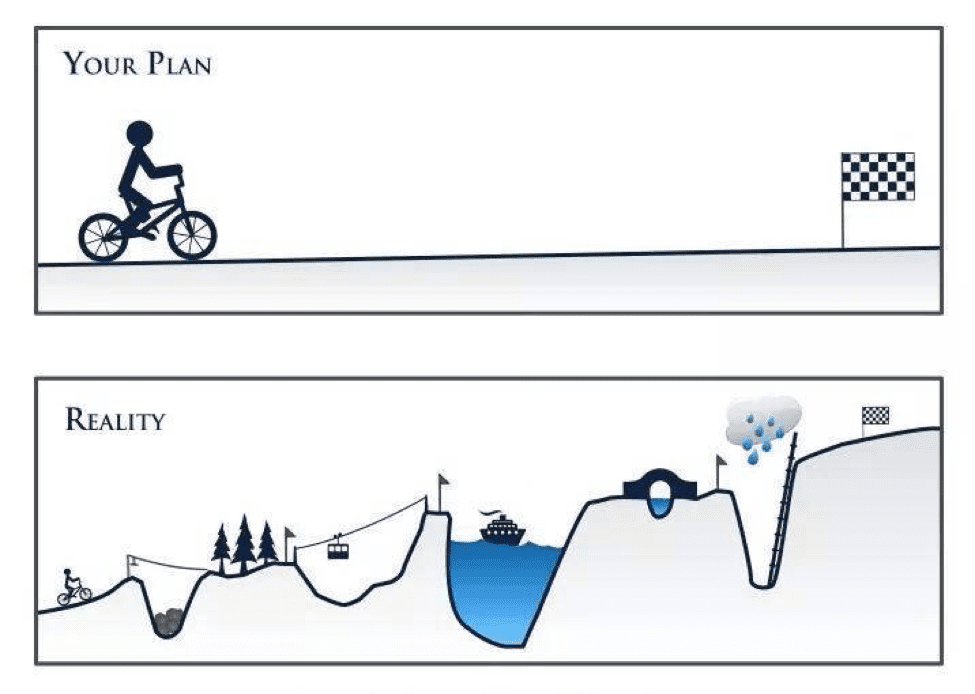
** L'enfer de la Recherche Reproductible
#  # http://thumbpress.com/wp-content/uploads/2014/04/funny-water-toy-kids-playing1.jpg
#+BEGIN_EXPORT html
# http://thumbpress.com/wp-content/uploads/2014/04/funny-water-toy-kids-playing1.jpg
#+BEGIN_EXPORT html
 #+END_EXPORT
Note:
Bonjour à tous,
Maintenant que vous êtes familiers avec les documents computationnels
et les analyses réplicables, vous disposez des outils principaux vous
permettant d'améliorer votre pratique et de rendre votre recherche
reproductible.
Mais la route est longue et semée d'embûches. Il est temps d'aller un
peu plus loin et que vous preniez consciences des différentes
difficultés auxquelles vous risquez d'être confronté.
Dans ce dernier module, nous vous présenterons trois des enfers de la
recherche reproductible.
** Module 4. Vers une étude reproductible : la réalité du terrain
1. L'enfer des données
2. L'enfer du logiciel
3. L'enfer du calcul
4. Conclusion
Note:
Christophe: Le premier enfer est celui des données. Quand on travaille
sur de vrais données, leur taille, leur structure, ou leur diversité
peuvent rapidement poser d'importantes difficultés. Je présenterai
quelques approches permettant de survivre dans cet environnement
hostile.
Arnaud: Le second enfer est celui du logiciel et on se trouve
rapidement confronté à deux défis. D'une part, le logiciel devient
très rapidement gros, difficile à gérer, et les solutions simples que
nous vous avons présentées passent alors très mal à
l'échelle. D'autre part, aussi étonnant que cela puisse paraître, les
logiciels vieillissent et résistent souvent très mal à l'épreuve du
temps. Je présenterai des exemples concrets et quelques approches
permettant de survivre dans cet environnement hostile.
Konrad: Enfin, le troisième enfer est celui du calcul
numérique. J'illustrerai les difficultés que peut poser le calcul avec
des flottants, ou l'ordre des opérations influe sur les
résultats. Comme cet ordre a aussi un impact sur la performance, il
faut trouver un compromis entre temps d'exécution et
reproductibilité. Ceci est particulièrement difficile pour le calcul
parallèle, qui concerne tous les ordinateurs modernes, même les
smartphones. J'évoquerai aussi les précautions à prendre quand on
utilise les nombres aléatoires.
En espérant ne pas vous avoir trop effrayés, nous concluerons enfin
brièvement ce MOOC par quelques remarques de bon sens.
* C028AL-W2-S1 (\approx 10:00); L'enfer des données
** Vers une étude reproductible : la réalité du terrain
_Module 4. Vers une étude reproductible : la réalité du terrain_
1. *L'enfer des données*
2. L'enfer du logiciel
3. L'enfer du calcul
4. Conclusion
#+BEGIN_EXPORT html
+++
## Deux « nouveaux » problèmes
Lorsque nous commençons à travailler sur de « vraies » données nous nous trouvons généralement confrontés à deux problèmes :
- les données sont de nature « diverse »
- les données occupent un grand espace mémoire
+++
## Les données « non homogènes »
- Les données grippales du module 3 se prêtent bien à une présentation en table (objet à 2 dimensions)
- Souvent la forme table doit être *abandonnée* car :
- les colonnes n'ont pas la même longueur
- les données peuvent être des suites chronologiques **et** des images, etc.
+++
## Les données sont « trop grosses »
- **Format texte** pas toujours approprié pour des nombres
- Choix d'un **format binaire** car :
- Les nombres prennent moins de place mémoire
- Nombres en format texte ⇒ conversion en binaire pour calculs
+++
## Ce qu'il faut garder du format texte : les métadonnées
- Le format texte permet de stocker les données **et** tout le reste...
- ⇒ ajouter des informations sur les données :
- provenance
- date d'enregistrement
- source
- etc.
+++
##
#+END_EXPORT
Note:
Bonjour à tous,
Maintenant que vous êtes familiers avec les documents computationnels
et les analyses réplicables, vous disposez des outils principaux vous
permettant d'améliorer votre pratique et de rendre votre recherche
reproductible.
Mais la route est longue et semée d'embûches. Il est temps d'aller un
peu plus loin et que vous preniez consciences des différentes
difficultés auxquelles vous risquez d'être confronté.
Dans ce dernier module, nous vous présenterons trois des enfers de la
recherche reproductible.
** Module 4. Vers une étude reproductible : la réalité du terrain
1. L'enfer des données
2. L'enfer du logiciel
3. L'enfer du calcul
4. Conclusion
Note:
Christophe: Le premier enfer est celui des données. Quand on travaille
sur de vrais données, leur taille, leur structure, ou leur diversité
peuvent rapidement poser d'importantes difficultés. Je présenterai
quelques approches permettant de survivre dans cet environnement
hostile.
Arnaud: Le second enfer est celui du logiciel et on se trouve
rapidement confronté à deux défis. D'une part, le logiciel devient
très rapidement gros, difficile à gérer, et les solutions simples que
nous vous avons présentées passent alors très mal à
l'échelle. D'autre part, aussi étonnant que cela puisse paraître, les
logiciels vieillissent et résistent souvent très mal à l'épreuve du
temps. Je présenterai des exemples concrets et quelques approches
permettant de survivre dans cet environnement hostile.
Konrad: Enfin, le troisième enfer est celui du calcul
numérique. J'illustrerai les difficultés que peut poser le calcul avec
des flottants, ou l'ordre des opérations influe sur les
résultats. Comme cet ordre a aussi un impact sur la performance, il
faut trouver un compromis entre temps d'exécution et
reproductibilité. Ceci est particulièrement difficile pour le calcul
parallèle, qui concerne tous les ordinateurs modernes, même les
smartphones. J'évoquerai aussi les précautions à prendre quand on
utilise les nombres aléatoires.
En espérant ne pas vous avoir trop effrayés, nous concluerons enfin
brièvement ce MOOC par quelques remarques de bon sens.
* C028AL-W2-S1 (\approx 10:00); L'enfer des données
** Vers une étude reproductible : la réalité du terrain
_Module 4. Vers une étude reproductible : la réalité du terrain_
1. *L'enfer des données*
2. L'enfer du logiciel
3. L'enfer du calcul
4. Conclusion
#+BEGIN_EXPORT html
+++
## Deux « nouveaux » problèmes
Lorsque nous commençons à travailler sur de « vraies » données nous nous trouvons généralement confrontés à deux problèmes :
- les données sont de nature « diverse »
- les données occupent un grand espace mémoire
+++
## Les données « non homogènes »
- Les données grippales du module 3 se prêtent bien à une présentation en table (objet à 2 dimensions)
- Souvent la forme table doit être *abandonnée* car :
- les colonnes n'ont pas la même longueur
- les données peuvent être des suites chronologiques **et** des images, etc.
+++
## Les données sont « trop grosses »
- **Format texte** pas toujours approprié pour des nombres
- Choix d'un **format binaire** car :
- Les nombres prennent moins de place mémoire
- Nombres en format texte ⇒ conversion en binaire pour calculs
+++
## Ce qu'il faut garder du format texte : les métadonnées
- Le format texte permet de stocker les données **et** tout le reste...
- ⇒ ajouter des informations sur les données :
- provenance
- date d'enregistrement
- source
- etc.
+++
##
- Ces informations sur les données sont ce qu'on appelle les **métadonnées**
- Elles sont vitales pour la mise en œuvre de la recherche reproductible
+++
## Ce qu'il faut garder du format texte : le boutisme
- Format texte « universel »
- Formats binaires dépendent de l'architecture ou de l'OS
- 1010, codé sur 4 bits peut être lu comme :
- 1x1 + 0x2 + 1x4 + 0x8 = 5, c'est le *petit-boutisme*
- 1x8 + 0x4 + 1x2 + 0x1 = 10, c'est le *gros-boutisme*
- **Un stockage binaire pour la recherche reproductible doit spécifier le boutisme**
+++
## Des formats binaires, pour données composites, permettant le sauvegarde de métadonnées
Rechercher des formats binaires pour :
- travailler avec de grosses données de natures différentes
- stocker des métadonnées avec les données
- avoir un boutisme fixé **une fois pour toute**
+++
## `FITS` et `HDF5`
- Le *Flexible Image Transport System* (`FITS`), créé en 1981 est toujours régulièrement mis à jour
- Le *Hierarchical Data Format* (`HDF`), développé au *National Center for Supercomputing Applications*, il en est à sa cinquième version, `HDF5`
+++
## `FITS`
- `FITS` introduit et mis à jour par les astrophysiciens
- Format suffisamment général pour utilisation dans différents contextes
+++
## Anatomie d'un fichier `FITS`
- 1 ou plusieurs segments : *Header/Data Units* (HDUs)
- HDU constituée :
- d'une en-tête (*Header Unit*) suivie, *mais ce n'est pas obligatoire*, par
- des données (*Data Unit*)
- En-tête = paires mots clés / valeurs → **métadonnées**
- Données tableaux binaires (une à 999 dimensions) ou tables (texte ou binaire)
+++
## Manipulation des fichiers `FITS`
- Les développeurs du format fournissent une bibliothèque `C` et des programmes associés (faciles à utiliser)
- Les utilisateurs de `Python` pourront utiliser `PyFITS`
- Les utilisateurs de `R` pourront utiliser `FITSio`
+++
## `HDF5`
- Organisation hiérarchique, ressemble à une arborisation de fichiers
- Élément structurant : le *group* (répertoire) contient un ou plusieurs *datasets* (jeux de données)
- Les *groups* peuvent être imbriqués
- Les métadonnées n'ont pas de structure imposée
- Les données n'ont pas de structure imposée — elles peuvent être des textes.
+++
## Manipulation des fichiers `HDF5`
- Format plus souple ⇒ bibliothèque `C` plus compliquée que son équivalent `FITS`
- La bibliothèque distribuée avec `HDFView` : outil puissant d'exploration et de visualisation
- `Python` dispose d'une interface très complète avec `h5py`
- Il y a trois paquets `R` : `h5`, `hdf5r` et `rhdf5`
+++
## L'archivage
Git (hub, lab, ...) : pas bien adapté au stockage de données

 +++
## Conclusions
- Vraies données ⇒ problèmes de taille et de structure
- Vraies données complexes ⇒ métadonnées
- `FITS` et `HDF5` = solutions **pratiques**
- En complexité et flexibilité : `FITS` < `HDF5`
- Plates-formes d'archivage ⇒ stockage pérenne accessible à tous
#+END_EXPORT
* C028AL-W2-S2 (\approx 14:00); L'enfer du logiciel
** Vers une étude reproductible : la réalité du terrain
_Module 4. Vers une étude reproductible : la réalité du terrain_
1. L'enfer des données
2. *L'enfer du logiciel*
3. L'enfer du calcul
4. Conclusion
** Passage à l'échelle file:assets/img/il-marche-mon-programme.jpg&size=contain
** Des codes complexes...
#+BEGIN_HTML
+++
## Conclusions
- Vraies données ⇒ problèmes de taille et de structure
- Vraies données complexes ⇒ métadonnées
- `FITS` et `HDF5` = solutions **pratiques**
- En complexité et flexibilité : `FITS` < `HDF5`
- Plates-formes d'archivage ⇒ stockage pérenne accessible à tous
#+END_EXPORT
* C028AL-W2-S2 (\approx 14:00); L'enfer du logiciel
** Vers une étude reproductible : la réalité du terrain
_Module 4. Vers une étude reproductible : la réalité du terrain_
1. L'enfer des données
2. *L'enfer du logiciel*
3. L'enfer du calcul
4. Conclusion
** Passage à l'échelle file:assets/img/il-marche-mon-programme.jpg&size=contain
** Des codes complexes...
#+BEGIN_HTML






 #+END_HTML
- Un vrai
plat de spaghettis
- Pas de
vision d'ensemble
-
Interaction entre plusieurs langages = danger
Note:
- Des codes compliqués à organiser/orchestrer. Le notebook a ses
limitations et vous pouvez en devenir prisonnier.
** ... et difficiles à orchestrer
#+BEGIN_HTML
#+END_HTML
- Un vrai
plat de spaghettis
- Pas de
vision d'ensemble
-
Interaction entre plusieurs langages = danger
Note:
- Des codes compliqués à organiser/orchestrer. Le notebook a ses
limitations et vous pouvez en devenir prisonnier.
** ... et difficiles à orchestrer
#+BEGIN_HTML

 #+END_HTML
Le *Workflow* :
- Vue de haut niveau plus claire
- Compositions de codes et mouvements de données explicites
- Partage, réutilisation, et exécution plus sûre
- Le notebook en est une forme à la fois appauvrie et plus riche
- Pas de façon simple/mature de passer d'un notebook à un
workflow
*Exemples* :
- Galaxy, Kepler, Taverna, Pegasus, Collective Knowledge, VisTrails
- Légers :
dask, drake, swift, snakemake, ...
- Hybrides :
SOS-notebook, ...
Note:
- un workflow, c'est quoi ? On restructure le code de façon à rendre
le flot de traitement plus explicite. Chaque bout de code est
encapsulé dans une fonction, on supprime les effets de bord pour que
les entrées et les sorties soient parfaitement identifiées. On
connecte ensuite chacune de ces fonctions les unes avec les
autres.
- Un environnement de workflow fournit les bonnes abstractions, les
bonnes conventions d'écritures permettant d'orchestrer tous ces
appels et c'est ensuite le moteur de workflow qui gère l'exécution
des choses. Non seulement le workflow peut plus facilement exploiter
une machine parallèle, mais en plus, il est possible de sauvegarder
l'état d'avancement du calcul (via les données générées jusqu'ici)
et le reprendre plus tard. Si on décide de modifier une des briques
du workflow, on peut réutiliser les résultats obtenus en amont. Ce
genre de manipulation est bien plus compliquée avec un notebook où
il y a une session, un état global et où le risque d'erreur est bien
plus important.
- Alors, un workflow peut devenir quelque chose de très compliqué et
de pas forcément très clair non plus mais la représentation par un
graphe permet de regrouper et d'agréger certaines parties pour se
concentrer sur l'essentiel tout en pouvant inspecter les détails
quand on le souhaite.
- Un autre avantages du workflow est la capacité à partager des
parties du workflow avec d'autres et à bénéficier des améliorations
que d'autres pourraient apporter à notre propre workflow... C'est un
des intérêt de plates-formes comme taverna ou kepler.
- Le notebook est donc selon moi parfait quand on met quelque chose au
point car il permet de prendre des notes sur ce que l'on fait
et sur pourquoi on le fait. Au fur et à mesure que le notebook
évolue en quelque chose de plus complexe et qu'on a les idées de
plus en plus claires sur les manipulations de données à effectuées,
il devient intéressant de transformer toute cette matière en un
workflow.
- Cette restructuration est manuelle et il n'existe pas encore de
bonne solution pour passer de l'un à l'autre. Il y a des tentatives
intéressantes comme le sos-notebook dans Jupyter mais toutes ces
initiatives sont encore en plein développement.
- L'utilisation d'un workflow ne rend pas l'utilisation d'un notebook
caduque. Le notebook est utile mais à un autre niveau. Les appels au
workflow peuvent parfaitement être faits à partir du notebook et on
utilisxe alors ce dernier pour décrire les expériences que l'on mène
et le résultats des analyses.
** L'usine à gaz des calculs coûteux
Les *calculs interminables* et les *gros volumes de données*
- JupyterHub et les supercalculateurs : en développement
#+END_HTML
Le *Workflow* :
- Vue de haut niveau plus claire
- Compositions de codes et mouvements de données explicites
- Partage, réutilisation, et exécution plus sûre
- Le notebook en est une forme à la fois appauvrie et plus riche
- Pas de façon simple/mature de passer d'un notebook à un
workflow
*Exemples* :
- Galaxy, Kepler, Taverna, Pegasus, Collective Knowledge, VisTrails
- Légers :
dask, drake, swift, snakemake, ...
- Hybrides :
SOS-notebook, ...
Note:
- un workflow, c'est quoi ? On restructure le code de façon à rendre
le flot de traitement plus explicite. Chaque bout de code est
encapsulé dans une fonction, on supprime les effets de bord pour que
les entrées et les sorties soient parfaitement identifiées. On
connecte ensuite chacune de ces fonctions les unes avec les
autres.
- Un environnement de workflow fournit les bonnes abstractions, les
bonnes conventions d'écritures permettant d'orchestrer tous ces
appels et c'est ensuite le moteur de workflow qui gère l'exécution
des choses. Non seulement le workflow peut plus facilement exploiter
une machine parallèle, mais en plus, il est possible de sauvegarder
l'état d'avancement du calcul (via les données générées jusqu'ici)
et le reprendre plus tard. Si on décide de modifier une des briques
du workflow, on peut réutiliser les résultats obtenus en amont. Ce
genre de manipulation est bien plus compliquée avec un notebook où
il y a une session, un état global et où le risque d'erreur est bien
plus important.
- Alors, un workflow peut devenir quelque chose de très compliqué et
de pas forcément très clair non plus mais la représentation par un
graphe permet de regrouper et d'agréger certaines parties pour se
concentrer sur l'essentiel tout en pouvant inspecter les détails
quand on le souhaite.
- Un autre avantages du workflow est la capacité à partager des
parties du workflow avec d'autres et à bénéficier des améliorations
que d'autres pourraient apporter à notre propre workflow... C'est un
des intérêt de plates-formes comme taverna ou kepler.
- Le notebook est donc selon moi parfait quand on met quelque chose au
point car il permet de prendre des notes sur ce que l'on fait
et sur pourquoi on le fait. Au fur et à mesure que le notebook
évolue en quelque chose de plus complexe et qu'on a les idées de
plus en plus claires sur les manipulations de données à effectuées,
il devient intéressant de transformer toute cette matière en un
workflow.
- Cette restructuration est manuelle et il n'existe pas encore de
bonne solution pour passer de l'un à l'autre. Il y a des tentatives
intéressantes comme le sos-notebook dans Jupyter mais toutes ces
initiatives sont encore en plein développement.
- L'utilisation d'un workflow ne rend pas l'utilisation d'un notebook
caduque. Le notebook est utile mais à un autre niveau. Les appels au
workflow peuvent parfaitement être faits à partir du notebook et on
utilisxe alors ce dernier pour décrire les expériences que l'on mène
et le résultats des analyses.
** L'usine à gaz des calculs coûteux
Les *calculs interminables* et les *gros volumes de données*
- JupyterHub et les supercalculateurs : en développement
- Checkpoint et Cache
- Le workflow permet de passer à l'échelle
Note:
# https://zonca.github.io/2015/04/jupyterhub-hpc.html
# https://github.com/ipython/ipyparallel/issues/167
# https://groups.google.com/forum/#!topic/jupyter/BlexhV8W5TE
Les calculs interminables et les gros volumes de données
- JupyterHub et les supercalculateurs: en développement
- Lancement sur des machines distantes ? Compliqué, pas de bonnes
solutions à l'heure actuelle.
- Actuellement, JupyterHub permet de donner une machine
(éventuellement virtuelle) à chaque notebook
- Il dispose également d'un onglet cluster permettant d'allouer
plusieurs machines à un Ipython parallèle.
- Lorsque l'on souhaite paralléliser c'est la plupart du temps le
langage du notebook qui fait le travail (Ipython parallèle, R au
dessus de spark, etc.), pas le notebook lui même.
- Notebook idéal selon moi: tel bloc peut/doit s'exécuter ailleurs
- Ce qui n'est pas sans poser de nombreux problèmes de sémantiques
(surtout si le mécanisme de session est utilisé et/ou que
plusieurs langages sont utilisés)
- Checkpoint et Cache:
- Il y a des mécanismes de cache dans les trois environnements que
nous vous avons présentés.
- Cela vous permet de ne pas tout réexécuter depuis le début.
- Ne pas confondre l'objet résultant (le graphique ou le tableau) des
données sous-jacentes.
- Un checkpoint explicite (via des fichiers) des données nécessaires
à la suite des calculs est la méthode la plus simple.
- Le workflow gère la séparation des codes et des données, ce qui
permet de passer à l'échelle
# - Histoire de montrer que malgré ça c'est dur:
# https://github.com/IFB-ElixirFr/ReproHackathon/blob/master/docs/index.md
# https://f1000research.com/articles/6-124/v1
** Des éco-systèmes complexes
Que se cache-t-il derrière ce simple
#+begin_src python :results output :exports both
import matplotlib
#+end_src
#+BEGIN_EXPORT html
Package: python3-matplotlib
Version: 2.1.1-2
Depends: python3-dateutil, python-matplotlib-data (>= 2.1.1-2),
python3-pyparsing (>= 1.5.6), python3-six (>= 1.10), python3-tz,
libjs-jquery, libjs-jquery-ui, python3-numpy (>= 1:1.13.1),
python3-numpy-abi9, python3 (<< 3.7), python3 (>= 3.6~),
python3-cycler (>= 0.10.0), python3:any (>= 3.3.2-2~), libc6 (>=
2.14), libfreetype6 (>= 2.2.1), libgcc1 (>= 1:3.0), libpng16-16 (>=
1.6.2-1), libstdc++6 (>= 5.2), zlib1g (>= 1:1.1.4)

#+END_EXPORT
Note:
- Qu'est-ce qui se cache derrière matplotlib
- Python peut nous dire ce qu'il en sait (i.e., pas grand chose)
mais comment s'assurer que deux personnes exécutent bien ce code
dans le même environnement logiciel
- Dans le cadre de ce MOOC, un serveur jupyter est déployé et un
environnemnt commun est proposé. Mais pouvez vous vous assurer que
vous disposerez du même environnemnt chez vous à la fin du MOOC ?
- Comment réinstaller un tel environnemnent ? Comment packager un
logiciel complexe ?
- Comment faire en sorte qu'il puisse évoluer si un bug est corrigé ?
** Des éco-systèmes complexes
Pas de standard
- Linux (=apt=, =rpm=, =yum=),
MacOS X (=brew=, =McPorts=, =Fink=), Windows (?)
- Ni pour l'installation ni pour récupérer les informations... \frowny
#+BEGIN_EXPORT html
#+END_EXPORT
#+begin_src python :results output :exports both
import sys
print(sys.version)
import matplotlib
print(matplotlib.__version__)
import pandas as pd
print(pd.__version__)
#+end_src
#+RESULTS:
: 3.6.3 (default, Oct 3 2017, 21:16:13)
: [GCC 7.2.0]
: 2.1.1
: 0.20.3
#+BEGIN_EXPORT html
#+END_EXPORT
#+begin_src R :results output :session *R* :exports both
library(ggplot2)
sessionInfo()
#+end_src
#+RESULTS:
#+begin_example
R version 3.4.3 (2017-11-30)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Debian GNU/Linux buster/sid
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.7.1
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.7.1
locale:
[1] LC_CTYPE=fr_FR.UTF-8 LC_NUMERIC=C
[3] LC_TIME=fr_FR.UTF-8 LC_COLLATE=fr_FR.UTF-8
[5] LC_MONETARY=fr_FR.UTF-8 LC_MESSAGES=fr_FR.UTF-8
other attached packages:
[1] ggplot2_2.2.1
loaded via a namespace (and not attached):
[1] colorspace_1.3-2 scales_0.5.0 compiler_3.4.3 lazyeval_0.2.1
[5] plyr_1.8.4 pillar_1.1.0 gtable_0.2.0 tibble_1.4.2
[9] Rcpp_0.12.15 grid_3.4.3 rlang_0.1.6 munsell_0.4.3
#+end_example
#+BEGIN_EXPORT html
#+END_EXPORT
Note:
- Pas de standard:
- Ni pour l'installation ni pour récupérer les informations:
- Linux (Debian =apt=, RedHat =rpm=, ...), MacOS X (=brew=, =McPorts=,
=Fink=), Windows (?)
- Indiquer ses dépendances logicielles, c'est la version 0 de la
reproductibilité. Ça ne coûte pas bien cher et ça permettra à
celui qui viendra après vous de savoir par où commencer.
- Il faut mettre en place une solution ad hoc, selon le langage
utilisé et ce n'est pas simple.
- Lister l'intégralité de ses dépendances logicielles (voire avec
quel compilateur telle bibliothèque a été compilée) peut être très
compliqué
** Contrôler son environnement
*Un environnement contrôlé :*
- Travailler dans une machine virtuelle (lourd) ou un conteneur docker
(léger)
#+BEGIN_EXPORT html
#+END_EXPORT
Note:
- Intro:
- You cannot expect people to find all the chains of dependencies!
- You cannot expect people to install all the dependencies and run your
code smoothly!
- Règle numéro 1 d'un environnement bien contrôlé: travailler dans un
environnement isolé (une machine virtuelle ou bien un conteneur)
- Brève explication de ce que c'est et de la différence. Sans le
savoir, tous ceux qui ont utilisé nos notebooks ont travaillé dans
un conteneur docker.
- Conséquence:
- du point de vue du code exécuté, tout est encapsulé: rien ne
rentre, rien ne sort
- l'utilisation de l'interface graphique peut être un peu compliquée
- exécution a priori possible sur n'importe quel OS (pour une VM,
sur un OS compatible pour un conteneur)
- Un environnement contrôlé: deux approches
- Conserver le bazar ::
- C'est l'approche toute automatique, un outil se charge
d'observer l'exécution de votre logiciel et de capturer
l'ensemble des codes et des bibliothèques utilisées
- Une archive contenant l'environnement peut alors être construite
et partagée. C'est très facile et très pratique.
- Avantage: Facile, permet à quelqu'un d'autre de réexécuter le
code dans les mêmes conditions
- Inconvénient: pas facile de faire évoluer un tel objet, ni de
comprendre comment il fonctionne. Le résultat est une boite
noire.
- Examples: CARE, CDE, Reprozip
- Faire le ménage ::
- On part d'un environnement minimal dans un conteneur
- On rajoute les composants logiciel dont on a besoin au fur et à
mesure
- Idéalement, au fur et à mesure qu'on rajoute ces logiciel, on
scripte leur installation (e.g., dockerfile)
- Avantage: cela permettra de facilement faire évoluer
l'environnement (mise à jour, remplacement d'un composant
défectueux, etc.)
- Inconvénient: demande quelques efforts, en particulier quand les
composants logiciels sont mal packagés (pas partie d'une
distribution, interventions manuelles, etc.) et que beaucoup
d'interactions avec l'extérieur sont nécessaires (le téléchargement
des données doit être bien séparé)
- Examples: Singularity, voire Nix ou GUIX qui permettent une
reconstruction parfaite, un environnement étant encodé de façon
fonctionnel
*** Cruft :noexport:
#+begin_src shell :results output raw :exports both
echo "#+BEGIN_EXAMPLE"
apt-cache show python3-matplotlib # | grep Depends | head -1
echo "#+END_EXAMPLE"
#+end_src
#+RESULTS:
#+BEGIN_EXAMPLE
Package: python3-matplotlib
Source: matplotlib
Version: 2.1.1-2
Installed-Size: 12159
Maintainer: Sandro Tosi
Architecture: amd64
Depends: python3-dateutil, python-matplotlib-data (>= 2.1.1-2), python3-pyparsing (>= 1.5.6), python3-six (>= 1.10), python3-tz, libjs-jquery, libjs-jquery-ui, python3-numpy (>= 1:1.13.1), python3-numpy-abi9, python3 (<< 3.7), python3 (>= 3.6~), python3-cycler (>= 0.10.0), python3:any (>= 3.3.2-2~), libc6 (>= 2.14), libfreetype6 (>= 2.2.1), libgcc1 (>= 1:3.0), libpng16-16 (>= 1.6.2-1), libstdc++6 (>= 5.2), zlib1g (>= 1:1.1.4)
Recommends: python3-pil, python3-tk
Suggests: dvipng, ffmpeg, gir1.2-gtk-3.0, ghostscript, inkscape, ipython3, librsvg2-common, python-matplotlib-doc, python3-cairocffi, python3-gi, python3-gi-cairo, python3-gobject, python3-nose, python3-pyqt4, python3-scipy, python3-sip, python3-tornado, texlive-extra-utils, texlive-latex-extra, ttf-staypuft
Enhances: ipython3
Description-fr: système de traçage basé sur Python dans un style similaire à celui Matlab –⋅Python⋅3
Matplotlib est une bibliothèque de traçage en Python pur conçue pour
apporter à Python des capacités de traçage d'une qualité adaptée à la
publication, avec une syntaxe familière aux utilisateurs de Matlab. L'accès
à toutes les commandes de traçage, dans l'interface pylab, est possible
soit à travers une interface fonctionnelle familière aux utilisateurs de
Matlab, soit à travers une interface orientée objet familière à ceux de Python.
.
Ce paquet fournit la version Python⋅3 de matplotlib.
Description-md5: 29e115db1f22ec2264a195b584329de9
Homepage: http://matplotlib.org/
Section: python
Priority: optional
Filename: pool/main/m/matplotlib/python3-matplotlib_2.1.1-2_amd64.deb
Size: 4597588
MD5sum: bfca8169a6b4e2cd9f89eb2f862083c7
SHA256: cbf80fdbf2643f19f926e33ea24cab3f76286d631d0806a2f665989fb17c76e4
Package: python3-matplotlib
Source: matplotlib
Version: 2.0.0+dfsg1-2
Installed-Size: 7362
Maintainer: Sandro Tosi
Architecture: amd64
Depends: python3-dateutil, python-matplotlib-data (>= 2.0.0+dfsg1-2), python3-pyparsing (>= 1.5.6), python3-six (>= 1.10), python3-tz, libjs-jquery, libjs-jquery-ui, python3-numpy (>= 1:1.10.0~b1), python3-numpy-abi9, python3 (<< 3.6), python3 (>= 3.5~), python3-cycler (>= 0.10.0), python3:any (>= 3.3.2-2~), libc6 (>= 2.14), libfreetype6 (>= 2.2.1), libgcc1 (>= 1:3.0), libpng16-16 (>= 1.6.2-1), libstdc++6 (>= 5.2)
Recommends: python3-pil, python3-tk
Suggests: dvipng, ffmpeg, gir1.2-gtk-3.0, ghostscript, inkscape, ipython3, librsvg2-common, python-matplotlib-doc, python3-cairocffi, python3-gi, python3-gi-cairo, python3-gobject, python3-nose, python3-pyqt4, python3-scipy, python3-sip, python3-tornado, texlive-extra-utils, texlive-latex-extra, ttf-staypuft
Enhances: ipython3
Description-fr: système de traçage basé sur Python dans un style similaire à celui Matlab –⋅Python⋅3
Matplotlib est une bibliothèque de traçage en Python pur conçue pour
apporter à Python des capacités de traçage d'une qualité adaptée à la
publication, avec une syntaxe familière aux utilisateurs de Matlab. L'accès
à toutes les commandes de traçage, dans l'interface pylab, est possible
soit à travers une interface fonctionnelle familière aux utilisateurs de
Matlab, soit à travers une interface orientée objet familière à ceux de Python.
.
Ce paquet fournit la version Python⋅3 de matplotlib.
Description-md5: 29e115db1f22ec2264a195b584329de9
Homepage: http://matplotlib.org/
Section: python
Priority: optional
Filename: pool/main/m/matplotlib/python3-matplotlib_2.0.0+dfsg1-2_amd64.deb
Size: 1589544
MD5sum: e8f0571243df303a9b1f37a8ebf8177d
SHA256: 8f5d3509d4f5451468c6de44fc8dfe391c3df4120079adc01ab5f13ff4194f5a
#+END_EXAMPLE
Pourquoi est-ce difficile ?
** L'épreuve du temps file:assets/img/soviet_space_shuttle.jpg&size=cover
** Compatibilité ascendante
- Python et tout son écosystème à évolution hyper rapide
#+begin_src shell :results output :exports both
python2 -c "print(10/3)"
python3 -c "print(10/3)"
#+end_src
#+RESULTS:
: 3
: 3.3333333333333335
#+HTML:  #+HTML:
#+HTML:
#+HTML:
#+HTML:  - Cortical Thickness Measurements (PLOS ONE,
June 2012): /FreeSurfer/: /differences were found between the Mac and
HP workstations and between Mac OSX 10.5 and OSX 10.6./
-
Incompatibilité de formats entre orgmode 7.*, 8.*, 9.*, etc.
Note:
- Petit exemple en python, le plus simple qui soit, une division:
- Le passage de python2 à python3 a introduit des changements
majeurs puisque la division par défaut qui était à l'origine une
division entière est devenue une division sur des flottants.
- Alors, certains diront que python2 et python3 doivent être
considérés comme deux langages distincts mais même si python2
reste maintenu et continue d'évoluer (doucement), quand tous les
efforts de l'écosystème se tournent vers python3, on est bien
obligé d'emboiter le pas...
- Il y a quelques mois, un de mes collègues qui était bien content
d'avoir utilisé un notebook pour préparer son dernier article et
d'avoir fait bien attention à sauvegarder tout son code et ses
résultats intermédiaires, a été assez surpris en préparant la
révision finale de remarquer que la figure qu'il avait générée 3
mois auparavant avait décidé de changer de couleurs...
- Entre les deux, matplotlib a été mis à jour sur sa machine et il
se trouve qu'entre la version 1.5.12 et la 2.0, la palette de
couleurs par défaut a changé...
- Alors, dans cet exemple précis, ça ne change pas
fondamentalement les choses et le plus important était de
pouvoir mettre à disposition la démarche utilisée mais c'est
quand même assez agaçant.
- Ce type d'incident met en évidence le problème de la perméabilité
à l'environnement extérieur.
** Les outils à développement rapide
*Rapides*, mais *fragiles* et *peu pérennes* :
#+BEGIN_EXPORT html
- Cortical Thickness Measurements (PLOS ONE,
June 2012): /FreeSurfer/: /differences were found between the Mac and
HP workstations and between Mac OSX 10.5 and OSX 10.6./
-
Incompatibilité de formats entre orgmode 7.*, 8.*, 9.*, etc.
Note:
- Petit exemple en python, le plus simple qui soit, une division:
- Le passage de python2 à python3 a introduit des changements
majeurs puisque la division par défaut qui était à l'origine une
division entière est devenue une division sur des flottants.
- Alors, certains diront que python2 et python3 doivent être
considérés comme deux langages distincts mais même si python2
reste maintenu et continue d'évoluer (doucement), quand tous les
efforts de l'écosystème se tournent vers python3, on est bien
obligé d'emboiter le pas...
- Il y a quelques mois, un de mes collègues qui était bien content
d'avoir utilisé un notebook pour préparer son dernier article et
d'avoir fait bien attention à sauvegarder tout son code et ses
résultats intermédiaires, a été assez surpris en préparant la
révision finale de remarquer que la figure qu'il avait générée 3
mois auparavant avait décidé de changer de couleurs...
- Entre les deux, matplotlib a été mis à jour sur sa machine et il
se trouve qu'entre la version 1.5.12 et la 2.0, la palette de
couleurs par défaut a changé...
- Alors, dans cet exemple précis, ça ne change pas
fondamentalement les choses et le plus important était de
pouvoir mettre à disposition la démarche utilisée mais c'est
quand même assez agaçant.
- Ce type d'incident met en évidence le problème de la perméabilité
à l'environnement extérieur.
** Les outils à développement rapide
*Rapides*, mais *fragiles* et *peu pérennes* :
#+BEGIN_EXPORT html
- Correction ou introduction de bug
- Il devient nécessaire de vérifier régulièrement la
reconstructibilité et la fonctionnalité de ces environnements
(intégration continue et tests de non régression)
Popper: 
#+END_EXPORT
*Autre possibilité* :
- Se restreindre à ce qui est maîtrisable (C par exemple)
Note:
- Les outils informatiques évoluent à une vitesse incroyable et nous
permettent d'aller plus vite, plus loin dans nos recherche. Il est
donc indispensable de s'appuyer dessus.
- Néanmoins, ces développements rapides sont aussi a source de
nombreuses erreurs, de régressions, de corrections (ce qui est une
bonne chose) et très souvent de perte de compatibilité entre les
versions.
- Ce sont des outils à développement rapide dans les deux sens du
terme, c'est à dire des outils qui à la fois vous permettent de
mettre en place des choses complexes très rapidement mais qui
évoluent aussi très (pour ne pas dire trop) rapidement.
- Dans ce contexte mouvant, il devient nécessaire de vérifier
régulièrement que notre code et son environnement peuvent être
regénérés et qu'ils sont fonctionnels. En génie logiciel, les termes
associés sont "intégration continue" (chaque nuit ou bien à chaque
commit dans votre gestionnaire de version, la compilation de votre
code est déclenchée et remonte une alerte en cas de problème) et
"tests de non régression" (une fois votre code et son environnement
compilé, on vérifie via une batterie de tests que les sorties pour
des entrées bien spécifiques sont toujours correctes).
- Certains proposent même une utilisation systématique de ce type
d'approche au processus de recherche. Ça demande un investissement
technique un peu lourd mais dans le principe, pourquoi pas ?
- Il faut garder à l'esprit que les notebooks ou les outils que nous
vous avons présentés font d'ailleurs partie de cette famille
d'outils à développement rapide et n'échappent pas malgré leurs
efforts à ces difficultés de pérennité.
- Pour être le moins possible ennuyé par ce type de problème, certains
font le choix de se restreindre à des outils et des langages très
stables et qu'ils peuvent maîtriser de bout en bout.
- Il faut donc trouver le bon compromis entre modernisme et pérennité.
** L'archivage
*Gestion du code source*
- Git (hub, lab, ...) : stables, ouverts, \dots pérennes ?
- Google Code, Gitorious, Code Spaces

 *Gestion des environnements*
- Pérénité de l'accès à dockerhub, nix repository, code ocean, ... ?
- Une fois l'environnement gelé, quelle est la pérennité d'une VM,
d'une image docker, ... ?
*Conserver le plus d'informations possible en automatisant*
-
Logiciels, versions, procédure d'installation
Note:
- Dans les exercices, faites y bien attention.
#
*Gestion des environnements*
- Pérénité de l'accès à dockerhub, nix repository, code ocean, ... ?
- Une fois l'environnement gelé, quelle est la pérennité d'une VM,
d'une image docker, ... ?
*Conserver le plus d'informations possible en automatisant*
-
Logiciels, versions, procédure d'installation
Note:
- Dans les exercices, faites y bien attention.
#  #
#
* C028AL-W2-S3 (\approx 10:00); L'enfer du calcul
** Vers une étude reproductible : la réalité du terrain
_Module 4. Vers une étude reproductible : la réalité du terrain_
1. L'enfer des données
2. L'enfer du logiciel
3. *L'enfer du calcul*
4. Conclusion
#+BEGIN_EXPORT html
Note:
Dans cette séquence, nous montrons les difficultés spécifiques qu'on
rencontre dans le calcul numérique. La plus fréquente est due à
l'arithmétique à virgule flottante, ce qui est un cas spécial de la
variabilité entre les plateformes de calcul. Une autre difficulté
est due aux générateurs de nombres aléatoires.
+++
## L'arithmétique à virgule flottante
#
#
* C028AL-W2-S3 (\approx 10:00); L'enfer du calcul
** Vers une étude reproductible : la réalité du terrain
_Module 4. Vers une étude reproductible : la réalité du terrain_
1. L'enfer des données
2. L'enfer du logiciel
3. *L'enfer du calcul*
4. Conclusion
#+BEGIN_EXPORT html
Note:
Dans cette séquence, nous montrons les difficultés spécifiques qu'on
rencontre dans le calcul numérique. La plus fréquente est due à
l'arithmétique à virgule flottante, ce qui est un cas spécial de la
variabilité entre les plateformes de calcul. Une autre difficulté
est due aux générateurs de nombres aléatoires.
+++
## L'arithmétique à virgule flottante
 ```
def polynome(x):
return x**9 - 9.*x**8 + 36.*x**7 - 84.*x**6 + 126.*x**5 \
- 126.*x**4 + 84.*x**3 - 36.*x**2 + 9.*x - 1.
```
Note:
Commençons avec un exemple. Mon collègue Arnaud a calculé les valeurs d'un
polynôme d'ordre 9. Le voici.
+++
## L'arithmétique à virgule flottante
```
def polynome(x):
return x**9 - 9.*x**8 + 36.*x**7 - 84.*x**6 + 126.*x**5 \
- 126.*x**4 + 84.*x**3 - 36.*x**2 + 9.*x - 1.
```
Note:
Commençons avec un exemple. Mon collègue Arnaud a calculé les valeurs d'un
polynôme d'ordre 9. Le voici.
+++
## L'arithmétique à virgule flottante
 ```
def horner(x):
return x*(x*(x*(x*(x*(x*(x*(x*(x - 9.) + 36.) - 84.) + 126.) \
- 126.) + 84.) - 36.) + 9.) - 1.
```
Note:
Mon collègue Christophe lui fait remarquer que la méthode de Horner résulte dans
un calcul plus efficace. Il s'agit d'un réarrangement des termes qui reduit notamment
le nombre de multiplications. Le voici. Les deux courbes se recouvrent, donc les
résultats sont identiques.
+++
## L'arithmétique à virgule flottante
```
def horner(x):
return x*(x*(x*(x*(x*(x*(x*(x*(x - 9.) + 36.) - 84.) + 126.) \
- 126.) + 84.) - 36.) + 9.) - 1.
```
Note:
Mon collègue Christophe lui fait remarquer que la méthode de Horner résulte dans
un calcul plus efficace. Il s'agit d'un réarrangement des termes qui reduit notamment
le nombre de multiplications. Le voici. Les deux courbes se recouvrent, donc les
résultats sont identiques.
+++
## L'arithmétique à virgule flottante
 ```
def simple(x):
return (x-1.)**9
```
Note:
Une analyse un peu plus approfondie montre que notre polynôme a une seule racine
à x=1, ce qui nous permet d'en simplifier le calcul. Nous avons maintenant
trois courbes qui se recouvrent. Tout va bien !
+++
## L'arithmétique à virgule flottante
```
def simple(x):
return (x-1.)**9
```
Note:
Une analyse un peu plus approfondie montre que notre polynôme a une seule racine
à x=1, ce qui nous permet d'en simplifier le calcul. Nous avons maintenant
trois courbes qui se recouvrent. Tout va bien !
+++
## L'arithmétique à virgule flottante
 Note:
Mais regardons la région autour de x=1 de plus près...
+++
## L'arithmétique à virgule flottante
Note:
Mais regardons la région autour de x=1 de plus près...
+++
## L'arithmétique à virgule flottante
 Note:
Ça a l'air un peu bizarre. Et les trois courbes ne sont enfin pas identiques,
juste proches. Qu'est-ce qui se passe ?
+++
## L'arrondi
Note:
Ça a l'air un peu bizarre. Et les trois courbes ne sont enfin pas identiques,
juste proches. Qu'est-ce qui se passe ?
+++
## L'arrondi
- Il y a un arrondi implicite dans chaque opération.
- a+b est en réalité *arrondi*(a+b).
- Mais *arrondi*(*arrondi*(a+b)+c) ≠ *arrondi*(a+*arrondi*(b+c)).
- L'ordre des opérations est donc important.
**Pour un calcul reproductible,
il faut préserver l'ordre des opérations !!**
Note:
Le résultat d'une opération arithmétique sur des flottant n'est en général pas
représentable par un autre flottant. On applique une opération d'arrondi qui
remplace le résultat exact avec une valeur proche qui est représentable.
A cause de l'arrondi, les règles habituelles de l'arithmétique ne sont plus
applicables à l'identique. On perd notamment l'associativité de l'addition et
de la multiplication.
En changeant l'ordre des opérations, on peut donc changer le résultat !
+++
## Comment l'expliquer à mon compilateur ?
Pour accélérer le calcul, les compilateurs peuvent changer l'ordre des opérations,
et donc le résultat.
Pour un calcul reproductible, il y a deux approches :
-
Insister sur le respect de l'ordre des opérations,
si le langage le permet.
Exemple : Le module `ieee_arithmetic` en Fortran 2003
-
Rendre la compilation reproductible :
- Noter la version précise du compilateur
- Noter toutes les options de compilation
Note:
Ceci devient un obstacle à la reproductibilité à cause des
optimisations appliquées par les compilateurs pour accélérer le
calcul. Celle-ci changent souvent l'ordre des opérations et donc le
résultat.
Pour rendre un calcul reproductible, il y a deux
approches. Premièrement, on peut dire à son compilateur de ne pas
toucher à l'ordre des opérations, idéalement dans le code source du
logiciel. Ceci est possible par exemple dans le langage Fortran
2003.
L'autre approche est de rendre la compilation elle-même
reproductible en notant la version précise du compilateur utilisé,
ainsi que toutes les options de compilation. Idéalement, il faut
alors archiver le compilateur avec le logiciel de calcul.
+++
## Calcul parallèle
- Objectif : une exécution plus rapide
⟶ Minimiser la communication entre processeurs
⟶ Adapter la répartition des données...
⟶ et donc l'ordre des opérations
- Conséquence : le résultat dépend du nombre de processeurs !
**Minimiser cet impact du parallélisme
reste un sujet de recherche.**
Note:
Un autre obstacle à la reproductibilité résulte du calcul parallèle.
Celui-ci a comme seul objectif une exécution plus rapide. Pour y arriver,
il faut minimiser la communication entre les processeurs en adaptant
la répartition des données. Ceci implique d'adapter l'ordre des opérations,
car chaque processeur traite d'abord ses données locales avant d'entrer en
communication avec les autres processeurs.
La conséquence est que le résultat du calcul change avec le nombre
de processeurs utilisés.
On peut tenter d'écrire le logiciel tel que l'impact de cette variation
soit minimisé. Mais il n'y a pour l'instant aucune technique éprouvée
pour y arriver. Ceci reste un sujet de recherche.
+++
## Calcul parallèle : exemple
 (Source : Thèse de Rafife Nheili, Université de Perpignan, 2016)
Note:
Regardons un simple exemple: la simulation des vagues causées dans
un bassin carré d'eau par une goutte qui tombe au milieu. A gauche,
la simulation exécutée sur un seul processeur. A droite, le résultat
d'un calcul sur quatre proecesseurs, ou les points qui diffèrent
sont colorés en gris.
+++
## Calcul parallèle : exemple
(Source : Thèse de Rafife Nheili, Université de Perpignan, 2016)
Note:
Regardons un simple exemple: la simulation des vagues causées dans
un bassin carré d'eau par une goutte qui tombe au milieu. A gauche,
la simulation exécutée sur un seul processeur. A droite, le résultat
d'un calcul sur quatre proecesseurs, ou les points qui diffèrent
sont colorés en gris.
+++
## Calcul parallèle : exemple
 (Source : Thèse de Rafife Nheili, Université de Perpignan, 2016)
Note:
Un pas de temps plus loin, le nombre de points à résultat différent
a nettement augmenté. Il continuera a augmenter au cours de la
simulation, jusqu'à ce qu'il n'y a plus aucun point pour lequel le
résultat restera identique.
+++
## Les plateformes de calcul
(Source : Thèse de Rafife Nheili, Université de Perpignan, 2016)
Note:
Un pas de temps plus loin, le nombre de points à résultat différent
a nettement augmenté. Il continuera a augmenter au cours de la
simulation, jusqu'à ce qu'il n'y a plus aucun point pour lequel le
résultat restera identique.
+++
## Les plateformes de calcul
- Plateforme de calcul : matériel + infrastructure logicielle
- Calcul = plateforme + logiciel + données
- La plateforme définit l'interprétation du logiciel.
- Plateforme et logiciel définissent l'interprétation des données.
- Autres aspects définis par la plateforme :
- la représentation des entiers (16/32/64 bits)
- la gestion des erreurs
Note:
Les obstacles à la reproductibilité dûs à l'arithmétique à virgule flottante
sont un cas spécial important de la dépendance des plateformes. Un logiciel
est écrit dans un langage de programmation, mais l'interprétation précise de
ce langage est définie par la plateforme de calcul utilisé. Celle-ci consiste
du matériel, notamment du processeur, et de l'infrastructure logiciel:
système d'exploitation, compilateurs, etc.
Un calcul est défini par trois ingrédients: la plateforme, le logiciel, et les
données traitées. La plateforme définit comment est interprété le logiciel,
et les deux ensembles définissent comment sont interprétées les donées.
L'arithmétique à virgule flottante est interprétée différemment par les différentes
plateformes de calcul populaires aujourd'hui, mais ce n'est pas le seul point
de divergence. Dans certains langage comme le C ou le Fortran, les entiers sont
aussi concernés car les plateformes leur attribuent des tailles et donc des
intervalles de valeurs différentes. Enfin, les erreurs de calcul, comme par
exemple la division par zéro, ne sont pas gérées de la ême façon par toutes les
plateformes.
+++
## Les nombres aléatoires
- Utilisés pour simuler les processus stochastiques.
- En pratique : nombres **pseudo-**aléatoires.
- Suite de nombres **en apparence** aléatoires...
- ... mais générés par un algorithme déterministe.
+++
## Générateur de nombres pseudo-aléatoires



 Note:
On part d'un état initial appelé "graine" (typiquement un entier).
Pour générer un nombre, on applique une transformation à cet état,
puis on calcule le nombre comme fonction de cet état.
On repète autant que nécessaire.
+++
## La reproductibilité en théorie
Note:
On part d'un état initial appelé "graine" (typiquement un entier).
Pour générer un nombre, on applique une transformation à cet état,
puis on calcule le nombre comme fonction de cet état.
On repète autant que nécessaire.
+++
## La reproductibilité en théorie
- Principe : même graine + même algorithme → même suite
- La graine est souvent choisie comme fonction de l'heure
- Il faut la définir dans le code d'application
Note:
En principe, il suffit d'utiliser la même graine et le même algorithme pour
toujours avoir la même suite de nombres.
L'algorithme fait partie d'une librairie, dont il faut noter la version
utilisée. Les librairie de nombres aléatoires choisissent souvent la graine
comme fonction de l'heure, pour donner une apparence "plus aléatoire".
Mais pour la reproductibilité, il faut définir la graine dans le code
d'application.
+++
## La reproductibilité en pratique
- Même graine + même algorithme → même suite :
pas évident en arithmétique à virgule flottante !
-
Un astuce simple pour permettre la vérification :
tester quelques valeurs du début de la suite.
Note:
En pratique, il n'est pas si facile d'obtenir une suite identique, même avec
la même version de la même librairie, à cause de la variation dans l'arithmétique
à virgule flottante.
Un astuce simple est de tester quelques valeurs du début de la suite. Si elle ne
sont pas identiques, on sait que la suite a changé.
+++
## Exemple : le langage Python
```
import random
random.seed(123)
for i in range(5):
print(random.random())
```
```
0.052363598850944326
0.08718667752263232
0.4072417636703983
0.10770023493843905
0.9011988779516946
```
Note:
Voici l'application de cet astuce en langage Python. On commence par
définir la graine et d'afficher les premières valeurs de la suit de
nombres pseudo-aléatoires.
+++
## Exemple : le langage Python
```
import random
random.seed(123)
assert random.random() == 0.052363598850944326
assert random.random() == 0.08718667752263232
assert random.random() == 0.4072417636703983
```
Note:
Puis on modifie le code en remplaçant l'affichage des valeurs par des
comparaisons aux valeurs précédemment affichées. En cas de divergence,
le programme s'arrête avec un message d'erreur.
+++
## Les points clés à retenir
- Les résultats d'un calcul dépendent
- du logiciel
- des données d'entrée
- de la plateforme de calcul : matériel, compilateurs, ...
- L'influence de la plateforme est importante pour l'arithmétique à virgule flottante.
- Notez les paramètres dont peuvent dépendre vos résultats :
- version du compilateur, options de compilation
- matériel (type de processeur, GPU, ...)
- nombre de processeurs
- En utilisant un générateur de nombres aléatoires, définissez la graine et vérifiez les premiers éléments de la suite.
#+END_EXPORT
* C028AL-W2-S4 (\approx 2:00); Conclusion
** Vers une étude reproductible : la réalité du terrain
_Module 4. Vers une étude reproductible : la réalité du terrain_
1. L'enfer des données
2. L'enfer du logiciel
3. L'enfer du calcul
4. *Conclusion*
** Ce qu'il faut retenir de ce MOOC
*Un véritable enjeu*
- Méthodologie scientifique
- Inspectabilité et réutilisation
*Des outils existent*
- Documents computationnels et Workflows, Suivi de version et
Archives, Environnements logiciels, Intégration continue, ...
- Ces outils évoluent en permanence
- Choisissez ceux qui sont les plus adaptés à votre contexte
- Cherchez un compromis entre modernisme et pérénité
*Mettez en pratique, ne vous découragez pas!*
- Prenez des notes rigoureusement
- Rendez l'information exploitable et accessible
- Améliorez petit à petit